Array data structure
In computer science, an array data structure or simply array is a data structure consisting of a collection of elements (values or variables), each identified by one or more integer indices, stored so that the address of each element can be computed from its index tuple by a simple mathematical formula.[1][2][3]
For example, an array of 10 integer variables, with indices 0 through 9, may be stored as 10 words at memory addresses 2000, 2004, 2008, … 2036 (this memory allocation can vary because some computers use other than 4 bytes to store integer type variables); so that the element with index i has address 2000 + 4 × i.[4]
Array structures are the computer analog of the mathematical concepts of vector, matrix, and to a certain extend tensor. Indeed, an array with one or two indices is often called a vector or matrix structure, respectively. Arrays are often used to implement tables, especially lookup tables; so the word table is sometimes used as synonym of array.
Arrays are among the oldest and most important data structures, and are used by almost every program and are used to implement many other data structures, such as lists and strings. They effectively exploit the addressing machinery of computers; indeed, in most modern computers (and many external storage devices), the memory is a one-dimensional array of words, whose indices are their addresses. Processors, especially vector processors, are often optimized for array operations.
Arrays are useful mostly because the element indices can be computed at run time. Among other things, this feature allows a single iterative statement to process arbitrarily many elements of an array. For that reason, the elements of an array data structure are required to have the same size and should use the same data representation. The set of valid index tuples and the addresses of the elements (and hence the element addressing formula) are usually,[3][5] but not always,[2] fixed while the array is in use.
The terms array and array structure are often used to mean array data type, a kind of data type provided by most high-level programming languages that consists of a collection of values or variables that can be selected by one or more indices computed at run-time. Array types are often implemented by array structures; however, in some languages they may be implemented by hash tables, linked lists, search trees, or other data structures.
The terms are also used, especially in the description of algorithms, to mean associative array or "abstract array", a theoretical computer science model (an abstract data type or ADT) intended to capture the essential properties of arrays.
Contents |
History
Array structures were used in the first digital computers, when programming was still done in machine language, for data tables, vector and matrix computations, and many other purposes. Von Neumann wrote the first array sorting program (merge sort) in 1945, when the first stored-program computer was still being built.[6]p. 159 Array indexing was originally done by self-modifying code, and later using index registers and indirect addressing. Some mainframes designed in the 1960s, such as the Burroughs B5000 and its successors, had special instructions for array indexing that included index bounds checking..
Assembly languages generally have no special support for arrays, other than what the machine itself provides. The earliest high-level programming languages, including FORTRAN (1957), COBOL (1960), and ALGOL 60 (1960), had support for multi-dimensional arrays, and so has C (1972). In C++ (1983), class templates exist for multi-dimensional arrays whose dimension is fixed at runtime[5][3] as well as for runtime-flexible arrays[2].
Applications
Arrays are used to implement mathematical vectors and matrices, as well as other kinds of rectangular tables. Many databases, small and large, consist of (or include) one-dimensional arrays whose elements are records.
Arrays are used to implement other data structures, such as heaps, hash tables, deques, queues, stacks, strings, and VLists.
One or more large arrays are sometimes used to emulate in-program dynamic memory allocation, particularly memory pool allocation. Historically, this has sometimes been the only way to allocate "dynamic memory" portably.
Arrays can be used to determine partial or complete control flow in programs, as a compact alternative to (otherwise repetitive), multiple IF statements. They are known in this context as control tables and are used in conjunction with a purpose built interpreter whose control flow is altered according to values contained in the array. The array may contain subroutine pointers (or relative subroutine numbers that can be acted upon by SWITCH statements) - that direct the path of the execution.
Addressing formulas
The number of indices needed to specify an element is called the dimension, dimensionality, or rank of the array.
In standard arrays, each index is restricted to a certain range of consecutive integers (or consecutive values of some enumerated type), and the address of an element is computed by a "linear" formula on the indices.
One-dimensional arrays
A one-dimensional array (or single dimension array) is a type of linear array. Accessing its elements involves a single subscript which can either represent a row or column index.
As an example consider the C declaration auto int new[10];
In the given example the array starts with auto storage class and is of integer type named new which can contain 10 elements in it i.e. 0-9. It is not necessary to declare the storage class as the compiler initializes auto storage class by default to every data type After that the data type is declared which is followed by the name i.e. new which can contain 10 entities.
For a vector with linear addressing, the element with index i is located at the address B + c · i, where B is a fixed base address and c a fixed constant, sometimes called the address increment or stride.
If the valid element indices begin at 0, the constant B is simply the address of the first element of the array. For this reason, the C programming language specifies that array indices always begin at 0; and many programmers will call that element "zeroth" rather than "first".
However, one can choose the index of the first element by an appropriate choice of the base address B. For example, if the array has five elements, indexed 1 through 5, and the base address B is replaced by B − 30c, then the indices of those same elements will be 31 to 35. If the numbering does not start at 0, the constant B may not be the address of any element.
Multidimensional arrays
For a two-dimensional array, the element with indices i,j would have address B + c · i + d · j, where the coefficients c and d are the row and column address increments, respectively.
More generally, in a k-dimensional array, the address of an element with indices i1, i2, …, ik is
- B + c1 · i1 + c2 · i2 + … + ck · ik
This formula requires only k multiplications and k−1 additions, for any array that can fit in memory. Moreover, if any coefficient is a fixed power of 2, the multiplication can be replaced by bit shifting.
The coefficients ck must be chosen so that every valid index tuple maps to the address of a distinct element.
If the minimum legal value for every index is 0, then B is the address of the element whose indices are all zero. As in the one-dimensional case, the element indices may be changed by changing the base address B. Thus, if a two-dimensional array has rows and columns indexed from 1 to 10 and 1 to 20, respectively, then replacing B by B + c1 - − 3 c1 will cause them to be renumbered from 0 through 9 and 4 through 23, respectively. Taking advantage of this feature, some languages (like FORTRAN 77) specify that array indices begin at 1, as in mathematical tradition; while other languages (like Fortran 90, Pascal and Algol) let the user choose the minimum value for each index.
Dope vectors
The addressing formula is completely defined by the dimension d, the base address B, and the increments c1, c2, … , ck. It is often useful to pack these parameters into a record called the array's descriptor or stride vector or dope vector[2][3]. The size of each element, and the minimum and maximum values allowed for each index may also be included in the dope vector. The dope vector is a complete handle for the array, and is a convenient way to pass arrays as arguments to procedures. Many useful array slicing operations (such as selecting a sub-array, swapping indices, or reversing the direction of the indices) can be performed very efficiently by manipulating the dope vector[2].
Compact layouts
Often the coefficients are chosen so that the elements occupy a contiguous area of memory. However, that is not necessary. Even if arrays are always created with contiguous elements, some array slicing operations may create non-contiguous sub-arrays from them.
There are two systematic compact layouts for a two-dimensional array. For example, consider the matrix
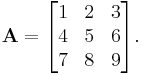
In the row-major order layout (adopted by C for statically declared arrays), the elements of each row are stored in consecutive positions:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
In Column-major order (traditionally used by Fortran), the elements of each column are consecutive in memory:
| 1 | 4 | 7 | 2 | 5 | 8 | 3 | 6 | 9 |
For arrays with three or more indices, "row major order" puts in consecutive positions any two elements whose index tuples differ only by one in the last index. "Column major order" is analogous with respect to the first index.
In systems which use processor cache or virtual memory, scanning an array is much faster if successive elements are stored in consecutive positions in memory, rather than sparsely scattered. Many algorithms that use multidimensional arrays will scan them in a predictable order. A programmer (or a sophisticated compiler) may use this information to choose between row- or column-major layout for each array. For example, when computing the product A·B of two matrices, it would be best to have A stored in row-major order, and B in column-major order.
Array resizing
Static arrays have a size that is fixed at allocation time and consequently do not allow elements to be inserted or removed. However, by allocating a new array and copying the contents of the old array to it, it is possible to effectively implement a dynamic or growable version of an array; see dynamic array. If this operation is done infrequently, insertions at the end of the array require only amortized constant time.
Some array data structures do not reallocate storage, but do store a count of the number of elements of the array in use, called the count or size. This effectively makes the array a dynamic array with a fixed maximum size or capacity; Pascal strings are examples of this.
Non-linear formulas
More complicated ("non-linear") formulas are occasionally used. For a compact two-dimensional triangular array, for instance, the addressing formula is a polynomial of degree 2.
Efficiency
Both store and select take (deterministic worst case) constant time. Arrays take linear (O(n)) space in the number of elements n that they hold.
In an array with element size k and on a machine with a cache line size of B bytes, iterating through an array of n elements requires the minimum of ceiling(nk/B) cache misses, because its elements occupy contiguous memory locations. This is roughly a factor of B/k better than the number of cache misses needed to access n elements at random memory locations. As a consequence, sequential iteration over an array is noticeably faster in practice than iteration over many other data structures, a property called locality of reference (this does not mean however, that using a perfect hash or trivial hash within the same (local) array, will not be even faster - and achievable in constant time). Libraries provide low-level optimized facilities for copying ranges of memory (such as memcpy) which can be used to move contiguous blocks of array elements significantly faster than can be achieved through individual element access. The speedup of such optimized routines varies by array element size, architecture, and implementation.
Memory-wise, arrays are compact data structures with no per-element overhead. There may be a per-array overhead, e.g. to store index bounds, but this is language-dependent. It can also happen that elements stored in an array require less memory than the same elements stored in individual variables, because several array elements can be stored in a single word; such arrays are often called packed arrays. An extreme (but commonly used) case is the bit array, where every bit represents a single element. A single octet can thus hold up to 256 different combinations of up to 8 different conditions, in the most compact form.
Array accesses with statically predictable access patterns are a major source of data parallelism.
Efficiency comparison with other data structures
| Array | Dynamic array |
Linked list |
Balanced tree |
|
|---|---|---|---|---|
| Indexing | Θ(1) | Θ(1) | Θ(n) | Θ(log n) |
| Insertion/deletion at end | N/A | Θ(1) | Θ(1) | Θ(log n) |
| Insertion/deletion in middle | N/A | Θ(n) | Θ(1) | Θ(log n) |
| Wasted space (average) | 0 | Θ(n) | Θ(n) | Θ(n) |
Growable arrays are similar to arrays but add the ability to insert and delete elements; adding and deleting at the end is particularly efficient. However, they reserve linear (Θ(n)) additional storage, whereas arrays do not reserve additional storage.
Associative arrays provide a mechanism for array-like functionality without huge storage overheads when the index values are sparse. For example, an array that contains values only at indexes 1 and 2 billion may benefit from using such a structure. Specialized associative arrays with integer keys include Patricia tries, Judy arrays, and van Emde Boas trees.
Balanced trees require O(log n) time for indexed access, but also permit inserting or deleting elements in O(log n) time,[7] whereas growable arrays require linear (Θ(n)) time to insert or delete elements at an arbitrary position.
Linked lists allow constant time removal and insertion in the middle but take linear time for indexed access. Their memory use is typically worse than arrays, but is still linear.
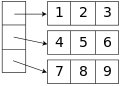
An Iliffe vector is an alternative to a multidimensional array structure. It uses a one-dimensional array of references to arrays of one dimension less. For two dimensions, in particular, this alternative structure would be a vector of pointers to vectors, one for each row. Thus an element in row i and column j of an array A would be accessed by double indexing (A[i][j] in typical notation). This alternative structure allows ragged or jagged arrays, where each row may have a different size — or, in general, where the valid range of each index depends on the values of all preceding indices. It also saves one multiplication (by the column address increment) replacing it by a bit shift (to index the vector of row pointers) and one extra memory access (fetching the row address), which may be worthwhile in some architectures.
Meaning of dimension
In computer science, the "dimension" of an array is its domain, namely the number of indices needed to select an element; whereas in mathematics it usually refers to the dimension of the set of all matrices, that is, the number of elements in the array. Thus, an array with 5 rows and 4 columns (hence 20 elements) is said to be "two-dimensional" in computing contexts, but "20-dimensional" in mathematics.
See also
Applications
- Register file
- Branch table
- Lookup table
- Bitmap
- Bit array
- Raster graphics
- String
- Suffix array
- Double-ended queue (deque)
- Heap
- Queue
- Stack
- Heap
- Hash table
Some array-based algorithms
- Counting sort
- Binary search algorithm
Technical topics
- Array slicing
- Content-addressable memory
- Index register
- Parallel array
- Offset (computer science)
- Random access
- Row-major order
- Stride of an array
Slight variants
- Dynamic array
- Variable-length array
Alternative structures for abstract tables
- Fusion tree
- Hashed array tree
- Hash array mapped trie
- Iliffe vector, used to implement mulidimensional arrays
- Judy array, a kind of hash table
- Linked list
- Sparse array
- VList, a list-array hybrid
Other
References
- ↑ Black, Paul E. (13 November 2008). "array". Dictionary of Algorithms and Data Structures. National Institute of Standards and Technology. http://www.nist.gov/dads/HTML/array.html. Retrieved 2010-08-22.
- ↑ 2.0 2.1 2.2 2.3 2.4 Bjoern Andres; Ullrich Koethe; Thorben Kroeger; Hamprecht (2010). "Runtime-Flexible Multi-dimensional Arrays and Views for C++98 and C++0x". arΧiv:1008.2909 [cs.DS].
- ↑ 3.0 3.1 3.2 3.3 Garcia, Ronald; Lumsdaine, Andrew (2005). "MultiArray: a C++ library for generic programming with arrays". Software: Practice and Experience 35 (2): 159–188. doi:10.1002/spe.630. ISSN 0038-0644.
- ↑ David R. Richardson (2002), The Book on Data Structures. iUniverse, 112 pages. ISBN 0-595-24039-9, 9780595240395.
- ↑ 5.0 5.1 T. Veldhuizen. Arrays in Blitz++. In Proc. of the 2nd Int. Conf. on Scientific Computing in Object-Oriented Parallel Environments (ISCOPE), LNCS 1505, pages 223-220. Springer, 1998.
- ↑ Donald Knuth, The Art of Computer Programming, vol. 3. Addison-Wesley
- ↑ Counted B-Tree
External links
|
||||||||||||||||||||